Introduction
This article explores how DBT (Data Build Tool) and Snowflake can be seamlessly used to create a powerful, error-resistant data pipeline. This pipeline processes raw data, ensures data integrity, and delivers actionable insights through dashboards.
Overview of DBT
DBT comes in two versions: the local development version (DBT Core) and the cloud-based version (DBT Cloud).
DBT Core:
- Open-Source Framework: DBT Core is the open-source version, a command-line tool and set of libraries used for transforming data in a data warehouse using SQL.
- Local Development: With DBT Core, you can develop and test your data models directly on your machine.
- Git Version Control: DBT Core integrates with version control systems like Git, enabling collaborative development, code versioning, and branching.
DBT Cloud:
- Managed Service: DBT Cloud is a cloud-based service offered by Fishtown Analytics (the creators of DBT). It provides a user-friendly interface for managing and running DBT in the cloud.
- Collaboration and Scheduling: DBT Cloud supports collaboration, scheduling, and running DBT jobs in a cloud environment, making it easy to monitor runs and share DBT artifacts with your team.
- Web-Based IDE: DBT Cloud includes a web-based Integrated Development Environment (IDE) for writing and running DBT code directly in the cloud.
- Versions: DBT Cloud is available in Developer, Team, and Enterprise versions, each offering different levels of features and collaboration tools.
DBT Development Process
The DBT development process typically follows a structured workflow. Below is an overview of the key stages:
- Environment Setup:
- Install DBT on your local machine or use a DBT Cloud instance.
- Connect DBT to your data warehouse by specifying the necessary credentials and connection details.
- Project Initialization:
- Create a new DBT project using the dbt init command.
- Configure your DBT profiles for the target data warehouse.
- Data Source Modeling:
- Define source models to transform raw data into meaningful tables or views.
- Use SQL to write transformations, aggregations, and calculations.
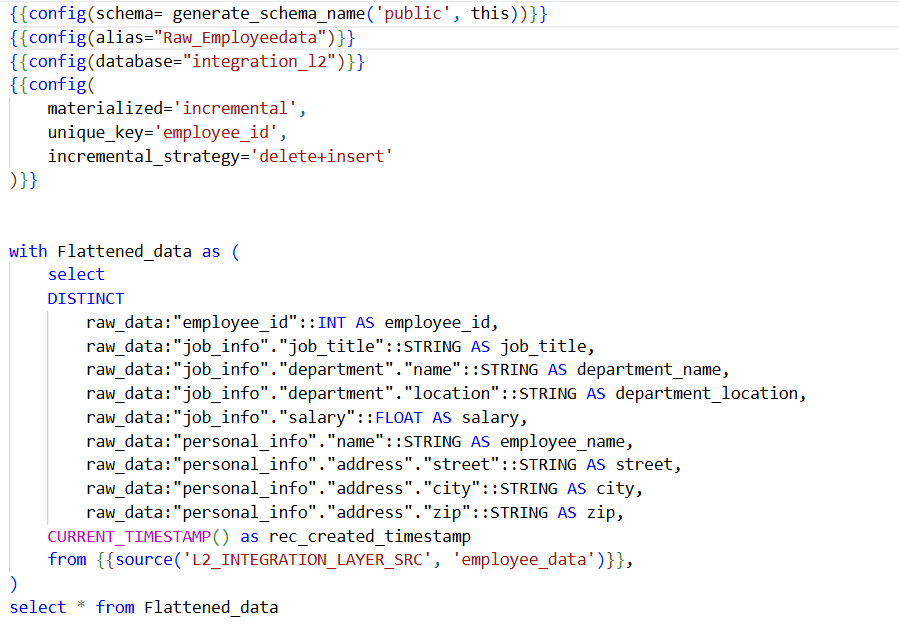
The example highlights “employee_data” as the source table and “raw_employee_data” as the target table. With this configuration, data will be ingested into the target table both as a full load and incrementally, using “employee_id” as the primary key. DBT allows the configuration of the schema and database to be used in the model.
- Dependency Management:
Specify dependencies between models using the ref function, establishing the order of execution.
- DBT automatically creates a Directed Acyclic Graph (DAG) based on these dependencies.
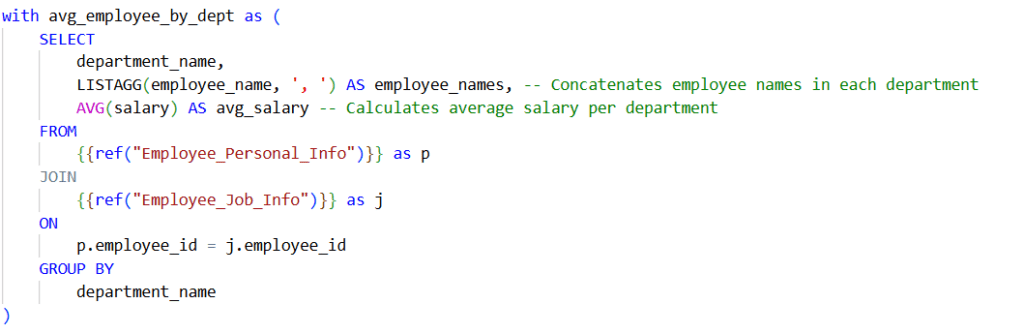
Below example demonstrates the use of the REF function with two DBT models, “employee_personal_info” and “employee_job_info.” This function allows data to be retrieved from these models, enabling the joining of the data to generate the desired output.
- Testing:
- Implement tests to ensure the correctness and reliability of your transformations.
- DBT supports schema tests, data tests, and custom tests.
- Documentation:
- Document your models, tests, and overall project using DBT’s built-in documentation features.
- Include descriptions, explanations of business logic, and other relevant information.
- Run and Validate:
- Execute DBT commands to run your models and tests.
- Validate the transformation results, addressing any errors or issues.
- Git Version Control:
- Store your DBT project in a version control system like Git.
- Use branches for feature development, bug fixes, and other changes. Collaborate with team members through pull requests and code reviews.
- Collaboration:
- Leverage DBT’s collaboration features to share and work on analytics code with your team.
- Use DBT Cloud or other collaboration tools to facilitate teamwork.
- Deployment:
- Deploy your DBT project to the production environment once changes are validated.
- Use DBT Cloud for scheduling and running DBT jobs in production.
- Monitoring and Maintenance:
- Monitor the performance of your DBT transformations in the production environment.
- Periodically review and update your DBT project to accommodate changes in data sources or business requirements.
DBT Integration and Benefits using Snowflake
DBT can be easily integrated with your Snowflake account, providing several benefits:
- Flexible Data Modelling: DBT separates environment configurations, target tables, and business logic, making complex data model development easier and more maintainable.
- Streamlined Deployment: Data models and code can be deployed across multiple environments, such as Dev, QA, and Prod, ensuring a smooth transition from development to production.
- Sequenced Execution: DBT allows you to define the execution order of data models according to business needs. DBT Cloud also offers DAG scheduling, eliminating the need of external scheduling tools like Airflow or Snowflake Tasks.
- Seamless Git Integration: DBT’s integration with Git simplifies version control, enabling multiple developers to collaborate effectively in the Cloud Team and Enterprise versions.
- Built-In Testing: Developers can write tests, define business rules, and run validations within DBT to ensure data quality.
- Code Reusability with Macros: Using Jinja templates, DBT allows developers to create reusable code, enhancing efficiency and reducing repetition.
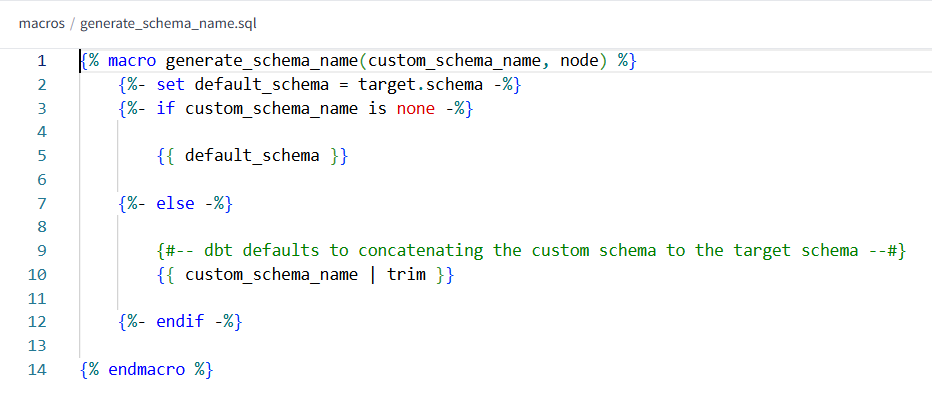
The example involves a system-defined macro that has been customized to configure our own schema, allowing the system to automatically generate the schema name.
- Data lineage: Data lineage allows developer to track flow and dependency of models.
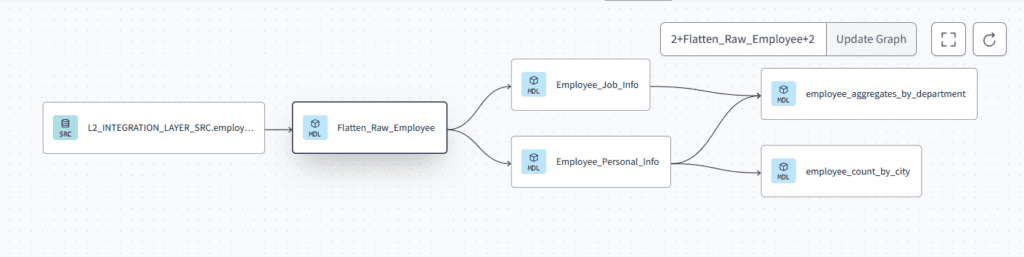
Data lineage in DBT show the flow of data using various DBT model. Here we can track how data flows through various views and tables. It begins with a source, passes through an initial transformation step, and then splits into two distinct models. These models process the data further, which is then used to generate specific aggregations and counts in the final step
- Reliable Data for Business Logic :
With data cleaned and validated, DBT applies more complex transformations in the business logic layer. Aggregations, joins, and other transformations align with specific business needs, ensuring that refined data is ready for accurate reporting and analysis.
Conclusion
Integrating DBT with Snowflake simplifies data transformation processes while ensuring data reliability and accuracy. By following a structured approach—starting with raw data ingestion, through rigorous transformation, and delivering insights via visualizations tools—this setup exemplifies how modern data tools can create powerful analytics solutions. This approach is ideal for organizations looking to build scalable, maintainable, and robust data pipelines using Snowflake.
About Authors
Saumya Annalkar – Saumya is a passionate data engineer with a strong enthusiasm for learning and mastering new technologies. Her expertise centers around AWS, Python, and Snowflake, where she focuses on designing and implementing data-driven solutions within the AWS and Snowflake environments.
Srinivass Talaulikar – Srinivass is a dedicated data engineer with a passion for leveraging AWS and Snowflake to build robust, data-driven solutions. With a focus on optimizing data workflows and enhancing data capabilities, he continuously seeks to master new technologies and deliver impactful results in the realm of data engineering.